この連載の第二回で紹介した拙作「英語例文検索 EReK」(//erek.ta2o.net/) は、
Web API (ウェブ検索API)を使って、
「ウェブ全体を巨大な一つのコーパスとみなす」ことにより、
コーパス検索を可能にするサービスでした。
今回は、普通のコーパス(ウェブだけではない大量のテキスト)
の検索についてです。
英国のリーズ大学 (University of Leeds) では、
英語、中国語、フランス語、日本語などの様々な言語の
大規模コーパスを作成しています
(参考 //corpus.leeds.ac.uk/list.html)。
ここでは、これらのコーパスを検索するインタフェースについて解説します。
Leeds collection of Internet corpora
//corpus.leeds.ac.uk/internet.html
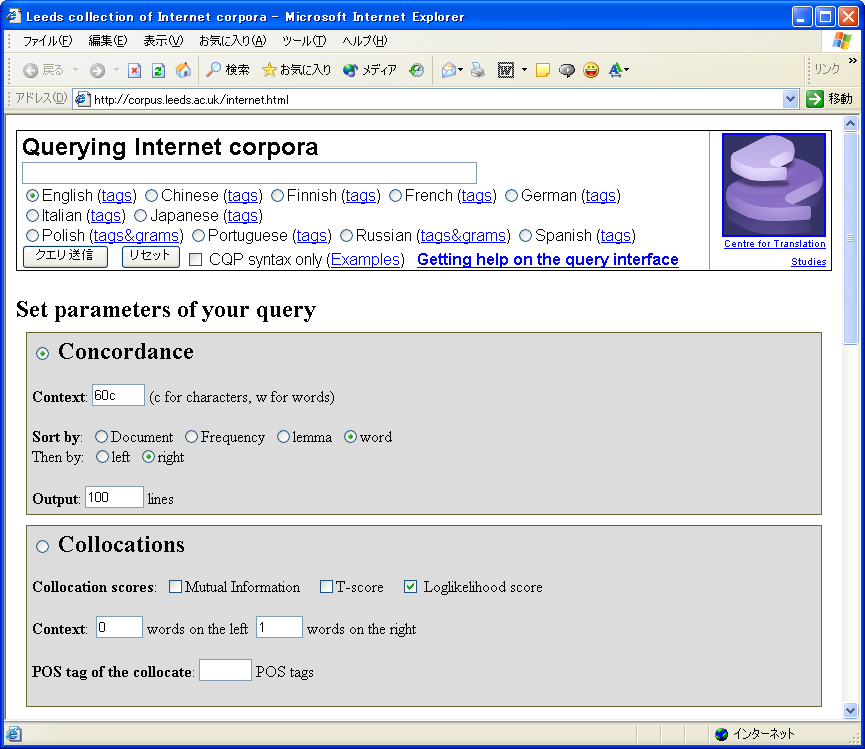
上記 URL のページで前述の様々な言語のコーパスを検索することができます。
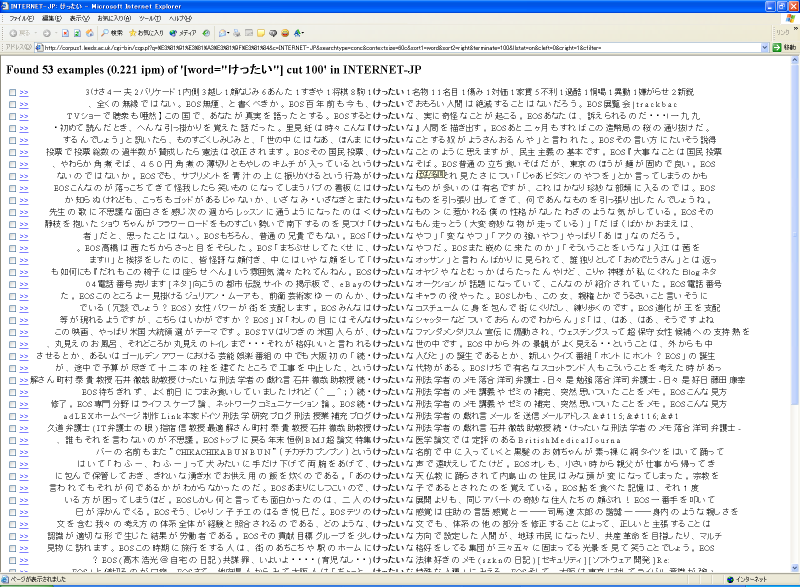
下図は、日本語を指定して単語「けったい」を検索した結果例です。
KWIC (中心に検索キーワードを左右に前後の文脈を配置する表示方式)
で検索結果が表示されます。
ブラウザを最大化して、文字を小さくしてから見ると良いでしょう。
各言語のコーパスは単語レベルの言語解析
(日本語だと「茶筌」による形態素解析)がされており、
コーパス検索結果の単語の上にマウスカーソルを乗せると、
品詞などの単語情報を見ることができます。
下図は、日本語と英語での例です。


また、品詞指定など検索時に細かい指定ができます。
Help ページ (//corpus.leeds.ac.uk/help.html) をご覧下さい。
ということで、
ウェブページそのものではなく、
しっかりと収集されたコーパスを検索できるサイトの一つとして、
リーズ大学の多言語コーパス検索サイトを紹介しました。
いろんな言語を同時に学びたい人にぴったりかもしれませんね。



